DIRISA Infrastructure
A vision for DIRISA infrastructure
In broad terms, DIRISA should provide the following components:
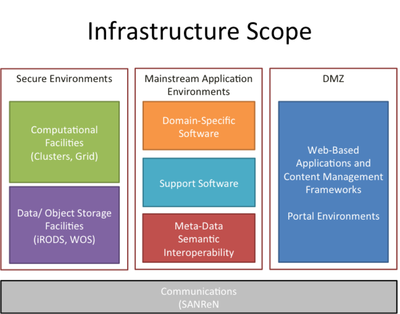
In this architecture, the primary (secure) services available to DIRISA will be based on computing facilities (HPC) and massive, replicated data storage (WOS). This provides for
- Distributed processing of data sets in a generalised, web processing paradigm;
- Replicated, policy-driven massive data storage, aimed at provision of seamless backup, fail-over and disaster recovery functions in addition to data management capabilities.
- This layer integrates with preservation management software, aimed at long-term management of information objects (see next section).
It is important to note that services and data need not be housed in the DIRISA facility, but can, in practice, be housed anywhere that resolves to a web location with a long-term lifetime. Good practice for data and services encourages management close to the owner or custodian, hence the DIRISA facilities will have to act as cloud-based environments under control of the data owner, and/or allow references to data and services outside its own network domains.
A second layer, which can be viewed as mediation or middleware components, are collected in a set of mainstream application environments. The main purpose of these components is to allow users to discover, work with, link, and collaborate on the data and services available to it through the data and services layers. It needs to provide:
- Meta-data management and semantic interoperability tools, assisting with discovery, application, and linkages of data and services;
- Specific Research Channel-enabling tools, including
- Multi-disciplinary or interdisciplinary research;
- Data preservation and curation;
- Linking research publications and data;
- Collaborative research.
- Domain-specific software, usually as client consumers of standardised data and services, which perform tasks such as visualisation, exploration, and analysis of data.
At the user interface layer, these components are presented to user communities in a content management paradigm, allowing management of visibility of objects, publication life cycles, and agile construction of ‘portal environments’ (Science or RDI Gateways). We foresee that these gateways will become increasingly simple to create for specific purposes, reflecting changes in user community preferences and focus, and that it should allow incorporation of non-DIRISA content and services to allow construction of e-Research and VREs by communities of practice.
In short:
- All domains require proper, efficient, and optimised infrastructure for meta-data repositories, searches, increasing use of semantic web tools and search brokerages, and so on.
- To the extent that the data is structured and multidimensional, it shares requirements in respect of
- data storage,
- data visualisation,
- analysis and processing,
- and large-scale data management.
- All domains require basic content management and user management infrastructure.
- All require long-term curation (preservation) procedures and infrastructure conforming to prescriptions for trusted digital repositories.
- Semantic integration between information objects and its meta-data layer is required to obtain cross-collation between domains.
- All of this requires infrastructure (software, hardware, and collateral[1]) as a base, and this base can be leveraged to serve additional requirements in the management of RDI output: specifically assisting NRF in pursuit of their policy of providing free and simplified access to research grant outputs.
DIRISA can easily be seen as a monolithic infrastructure service, but this is a mistake. While the facility provides ‘system’ capabilities to those stakeholders that require it, it should rather be viewed as an integration platform: the ‘glue’ that ensures cohesion between initiatives, projects, and communities of practice in the broad ambit of RDI outputs and its management (the “RDI/ Science Ecosystem”).
This is a critical point: DIRISA is purposely designed using ‘Service Oriented Architecture’ principles and adheres strictly to international interoperability specifications and standards. Hence, implementations that use DIRISA services in the background for meta-data storage, data archiving, data publication, discovery, and visualisation are a practical reality – all within a portal or website environment that has no obvious link to DIRISA at all.
[1] Standards architecture and a technical roadmap, documentation, implementation options, marketing and promotional materials, knowledge bases, user forums, service and product descriptions, service level agreements, and similar components of a ‘whole product’.
